A paradigm is a pattern or stylistic approach to doing or stating something. For example, when you prepare your resumé, you use a standard pattern, a paradigm, for formatting it. Another paradigm is the layout of the engine in a car --- although there are many different models of car, virtually all of them use the same design for their engine, frame, and drive train. Paradigms are useful to architects, who design skyscrapers with one paradigm and family residences with another. Writers use paradigms for stories, novels, and newspaper articles. Paradigms are used by scientists and engineers, too.
There are paradigms for thinking about and solving problems. We call these programming (language) paradigms.
There programming paradigms have been developed over the history of computing:
Do we do everyday tasks this way? Really, no. This programming paradigm comes from the computer hardware --- imperative programming is really all about reading and resetting hardware registers. This style of programming arose when hardware people got tired of rewiring computer hardware for each and every task --- they developed imperative programming notation that represents the wiring diagrams (that is, flow charts --- they are wiring diagrams!).
The standard beginner example is the function definition that
calculates the number of permutations of a collection of objects:
define factorial(n) = if n == 0
then return 1
else return n * factorial(n-1)
In this example, n is a nonnegative int (e.g., factorial(5) returns
120), but we can write
functions that compute on data structures, like lists and trees.
(Think of the functional solutions to tree traversal
and the Eight-Queens problem.)
The functional programming paradigm was developed, almost single-handedly, by John McCarthy at M.I.T. in the 1950s, who needed a computer language for natural-language processing. Since words and sentences can be arbitrary length, McCarthy was not happy using Fortran variables and fixed-length arrays. He started working with ``arrays that grew'' --- lists --- and he noticed that recursively defined functions (like factorial above) worked naturally for processing the words in a list.
McCarthy viewed a list as a hierarchical structure: a list has a ''top level'' (its front element) followed by all the levels (elements) underneath. The appropriate way to process a list to write an equation (function) that looks at the top level of the list and then calls itself to look at the remaining, lower levels, much like a cook peels an onion one layer at a time. McCarthy was comfortable with using recursively defined functions because he was trained in mathematics and recurrence equations.
The functional style works best with hierarchical data structures that can be processed one level at a time.
The structure of the puzzle and the clues are literally a program, because they are constraints for which the computer searches for a solution. In the logical/constraint programming paradigm, a program is a set of constraints, written as logical assertions, and a computation finds values for the variables (``empty squares'') mentioned in the logical assertions so that all the assections are made true. The variables are called logical variables, and they are like the empty squares of a puzzle. The logical assertions are like the clues to the puzzle. The computation tries various combinations of values to bind to the logical variables, trying to make true the logical assertions. If a combination of values does not succeed in making the assertions true, the computation backtracks (erases some of the values from the logical variables) and tries other combinations.
For example, 2 + 1 = X is a program (constraint) with one ``empty square,'' X, whose solution is X = 3, and X = X * X is a program (with one ``empty square,'' X) whose solution can be either X = 0 or X = 1.
The logical-programming paradigm is useful for solving problems in data bases, knowledge discovery, and learning: a data- or knowledge-base is coded as a set of logical assertions, and a query to the database is a logical assertion with variables that must receive values to answer the query. The paradigm was invented by computer scientists who studied resolution-based theorem proving; they noticed that a side-effect of constructing logic proofs that contained existential quantifiers, ∃X P(X), was that answers, a, for X were computed that made P(a) hold true. From here, it was a small step to adapting logic as a language for specifying computation of answers for such X.
It is best to think of communicative programming as ``collective programming,'' where, like the ant colony, a large collection of actors or objects work together in parallel to solve a problem. The primary advantage is speed within the parallel solution; the primary disadvantage is the huge overhead in coordinating the actors to combine their small parts of the solution. Often, the coordination overwhelms the computation and cancels the advantages of the parallelism.
Smalltalk-style object-oriented programming is a watered-down version of communicative programming, where each actor is provided substantial computational skills and the communication between actors is dramatically simplified to reduce the coordination overhead. Java and C# are modern variations of Smalltalk.
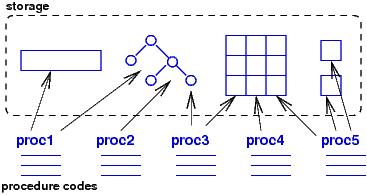
We review the four paradigms and focus on their machine models and storage layouts.
When one procedure wants to communicate or send data to another, the procedure places the data into one of the global data structures, calls the other procedure, and lets the other procedure look up the data in global storage. There is no notion of ownership of data, no notion of locality, and even no real need for arguments/parameters to procedures. The sequencing of variable lookups and updates is critical, and timing and race-condition errors often result.
It is easy to implement the imperative machine model on a von Neumann architecture because it is the von Neumann architecture! For this reason, the imperative model is widely used for writing system software.
One huge disadvantage of the imperative model is that there is no
simple way to deallocate and reuse storage. Here is the solution
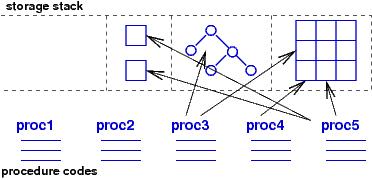
discoverd in the 1950's: If we arrange the global
storage like a stack, we can program the procedures
so that they ``push'' new data structures onto the global storage stack
and ''pop'' the structures when they are no longer needed.
Programming languages like Algol60 and Pascal used blocks and local
variables to indicate when data
are pushed and popped:
A namespace implements an actor/object; each actor ''knows'' the information in its owned data structure; it ``does'' the computations coded in its local methods; and it ''communicates'' knowledge by sending arguments/parameters to other methods and receiving answers in return. (Communication is needed when an actor requires knowledge from a data structure or method that it does not own.) Parameter passing and answer returning are essential to the paradigm; the arguments and results are usually small pieces of data --- numbers and words --- and not entire data structures.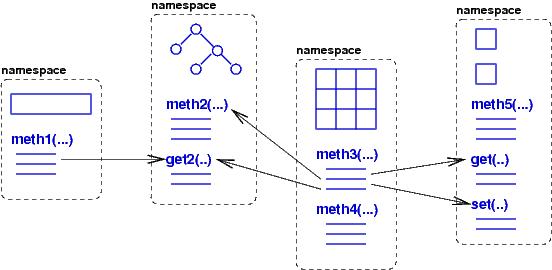
This machine model reduces errors due to abuse of data structures. Sequencing errors can still arise when a data structure's updates are applied in the wrong order because methods are called in the wrong order --- it is important to write the protocols for communication between actors.
We implement the machine model on a von Neumann machine by means of heap storage: namespaces (''objects'') are carved out of heap storage; each object is a mix of data structures and (pointers to) method code. There must also be an ``activation structure'' that remembers which methods in which objects are activated (executing). When the computer is a single-processor machine, the activation structure is organized as an activation stack.
The arguments and answers used by functions are complex data structures that must be assembled and disassembled by the functions at each call and return. This is an inconvenience, but the payoff is that there is no sharing of global variables so no race errors nor sequencing errors can arise --- each argument/answer is private data that a called function uses as it wishes.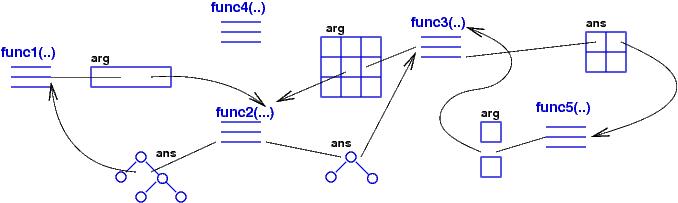
The functional machine model is implemented on a von Neumann machine by heap storage used to hold the argument- and answer-data-structures passed between functions. Since arguments and answers come-and-go frequently, there is a clean-up program, a garbage collector, that repeatedly scans heap storage and erases old, unused data structures.
There is a crucial efficiency trick here: since there are no assignment commands in a functional program, once a data structure argument/answer is assembled in the heap, it never changes. Thus, a constructed data structure can be shared and reused, reducing the time-space overhead of (re)building huge data structures as arguments and answers. All the pointer tricks you have learned come to good use when implementing the functional machine model.
Each clue is implemented as code that can fill some squares in the table with data and data structures. Because there are usually many different possibilities for filling in the empty squares, a conventional implementation strictly sequences the order of the clues updating the table. The updates are saved in a control stack that can be popped (''backtracked'') if the information in the table is filled in incorrectly or inconsistently; a backtrack step pops the control stack and erases from the table the information that was inserted by the popped update. Clues are tried repeatedly until a complete, consistent solution is entered into the table.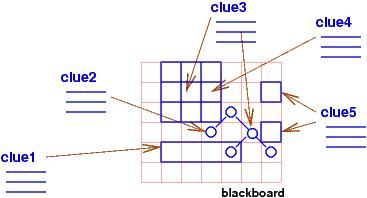
You will reach the point where it will be useful for you to share your knowledge, your libraries, your styles with others. Maybe you will share them with non-software engineers who use your work. At this point, you might wish to develop a language that is specialized to the domain and its problems. Such a language is called a domain-specific language. You use the language to talk about programs and their solutions. If you can state solutions (algorithms) in your domain-specific language, and if a computer can understand your domain-specific language (that is, you write an interpreter for your domain-specific language), then it is a domain-specific programming language.
You have probably hacked code in HTML --- it's a domain-specific language for web-page layout. You might have used a gamer package to create players and an environment for an interactive game; you have thus used a domain-specific language for gaming. And so it goes. Indeed, any nontrivial input format for an application is a domain-specific language, with its own a syntax and semantics --- language design and systems design go hand in hand.
When you design a domain-specific programming language, you will base it on a paradigm --- a machine model. The purpose of this course is to show you how to use some of standard paradigms and models to design your own languages.