Here is an ML function that returns the int that is least in a nonempty list of ints:
===================================================
(* least : int list -> int
returns the smallest int in NONEMPTY list, ns.
E.g., least [3,1,2] returns 1
least [4] returns 4
least [5, 3, 8, 3] returns 3 *)
fun least [n] = n
| least (n::ns) = let val m = least ns
in if n < m then n else m end
| least nil = raise Empty (* the "empty list" error. This equation is optional *)
===================================================
For example, least [3,2,7,8] returns 2. This is because
least [8] = 8
least [7,8] = 7
least [2,7,8] = 2
The recursive calls lead to least [3,2,7,8] = 2.
Now, make a file, Q1.sml, and place the above coding of least in it. Run it and test it with the above three test cases.
Next, code this function and add it to Q1.sml:
===================================================
(* remove : int * int list -> int list
builds an answer list that is exactly ns but with the first occurrence, if any, of m removed.
For example, remove(2, [3, 2 ,7]) returns [3, 7]
remove(2, [3, 2, 7, 2]) returns [3, 7, 2]
remove(2, [3]) returns [3]
*)
remove(m, nil) = ...
remove(m, (n::ns)) = ...
===================================================
Test your function on at least the three test cases listed above.
Here's the last part:
Selection sort repeatedly finds and moves the least element of a sequence to the front:
[3 2 5 1 4] => 1 [3 2 5 4] => 1 2 [3 5 4] => 1 2 3 [4 5] => 1 2 3 4 [5] => 1 2 3 4 5
You can understand the process as (i) finding the least element in the unsorted sequence, (ii) moving it to the front, (iii) repeating steps (i) and (ii) with what's left.
Use least and remove in your ML coding of selection sort, which you
add to Q2.sml:
===================================================
(* ssort : int list -> int list uses the selection-sort strategy to build
a list that contains the ints in the argument list, sorted in ascending order
E.g., ssort [3,2,5,1,4] returns [1,2,3,4,5]
ssort [3] returns [3]
ssort [3,2,1,2] returns [1,2,2,3]
*)
fun ssort nil = ... (* empty-list case *)
| ssort xs = ... (* non-empty list case *)
===================================================
Test your function on at least the three test cases listed above.
Save the output from all your tests in the file, Q1tests.txt.
datatype IntTree = Leaf | Node of int * IntTree * IntTreeNow, code this function, using any of the functions you have encountered so far on lists and trees:
===================================================
(* sumInts : IntTree -> int
adds up all the ints contained in InTree t and returns the total.
Examples: sumInts (Node(3, Node(2, Leaf, Node(4, Leaf, Leaf)), Leaf)) = 9
sumInts (Leaf) = 0
*)
===================================================
Test your function on the two test cases listed above.
Copy and paste your output from the test cases into a file, Q2tests.txt
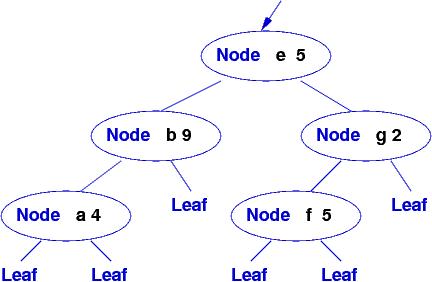
The database you will modify is a binary-search tree (ordered tree) holding (key,value) pairs, where a key is a single character and a value is an int. Here is an example database:
In SML, this database's type is defined
datatype DB = Leaf | Node of (char * int * DB * DB)
and the usual binary search (lookup) is done like this:
(* lookup: char * DB -> int searches for a key in a database (search tree)
and returns the int value saved with the key. *)
fun lookup(key, Leaf) = raise Empty (* empty-data-structure error *)
| lookup(key, Node(k, v, left, right)) =
if key = k then v
else if key < k then lookup(key, left)
else (* key >= k *) lookup(key, right)
The lookup is fast: a maximum of log2N nodes will be searched, where N is the number of entries in the database
(e.g., at most 11 nodes searched to find an item in a database of approx. 1000 entries; at most 21 nodes searched to find an item in a database of one million entries).
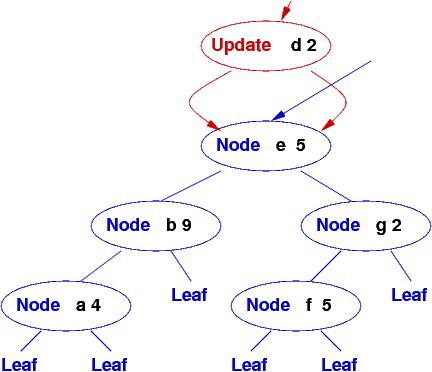
Say that a new key,value pair, "d", 2, must be added to the database. The standard, destructive update alters the database by removing a leaf and adding a node, like this:
This will crash those searches that are using the tree along the path as the update. Also, if the update must be rolled back, then the tree must be destructively altered again --- more trouble.
How do we alter the database without crashing the active searches on it?
The classic, nondestructive update in ML-style goes like this:
(* insert(k, v, db) adds (k,v) into the database, db, constructing
a new database that shares as much of db as possible. *)
fun insert(k, v, Leaf) = Node(k, v, Leaf, Leaf)
| insert(k, v, Node(kk, vv, left, right)) =
if k = kk then Node(k, v, left, right)
else if k < kk then Node(kk, vv, insert(k, v, left), right)
else (* k > kk *) Node(kk, vv, left, insert(k, v, right))
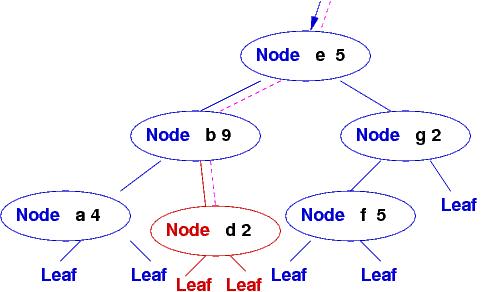
Here's a diagram of what the insertion of "d", 2 does with the above function:
A new "spine" is built, consisting of copies of all the nodes traversed to the insertion point. The other parts of the original database are shared. On the order of log2N new nodes must be constructed, where N is the number of entries in the database. This is a slightly expensive price to pay for inserting one new entry, but at least the original tree is unharmed, and lookups on the original nodes still complete in order log2N-time.
datatype DB = Leaf | Node of (char * int * DB * DB) | Update of (char * int * DB * DB)
The lookup algorithm operates the same, because the Update node steers lookups for those keys not-equal-to "d" downwards into the original tree. Also, it is trivial to roll back the update --- we merely reuse the orginal entry point into the original database!
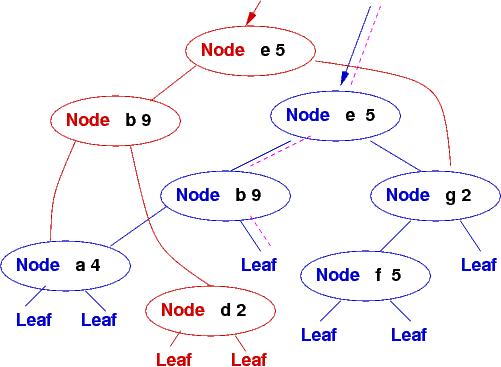
Alas, this simple strategy has a flaw: if there are multiple updates, a linear chain accumulates at the entry point:
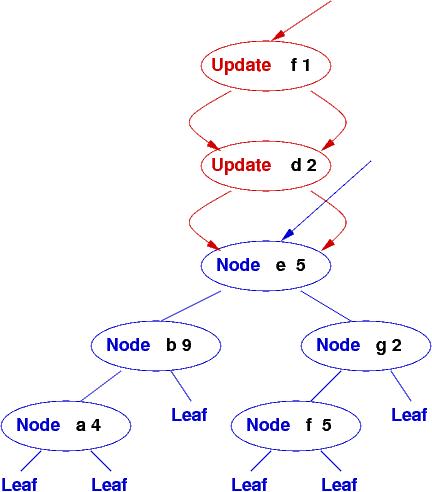
and all lookups quickly slow down from order log-time (log2N) to order linear time (N), which is unacceptable.
You will modify the naive insertion algorithm I have written so that it links each Update node to the appropriate subtrees, preserving more of the log-time lookups. Here is what the insertions look like using the improved algorithm:
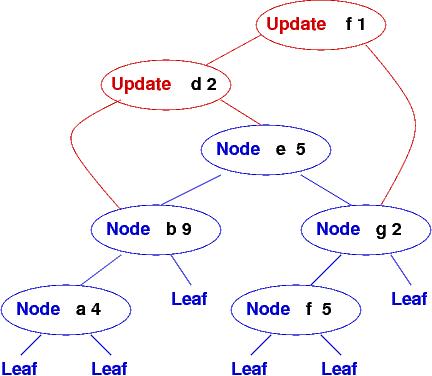
When it is time to commit (make permanent) the updates, the database is traversed and rebuilt as a balanced search tree:
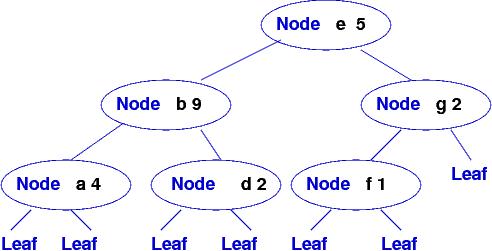
You must write the traversal algorithm that collects the contents of the updated tree so that the balanced tree can be constructed.
The code you start from is at www.cis.ksu.edu/~schmidt/505f14/Exercises/Ex4/Q3.sml. Save it as Q3.sml.
Say we start with this list of entries to initialize the database:
[(#"a",4), (#"b",9), (#"e",5), (#"f",5), (#"g",2)].
(Note: in SML, #"a" means the char, 'a', and "a" means the string, "a". Sorry about this.)
We type the following in the command window:
sml
use "Q3.sml";
run [(#"a",4), (#"b",9), (#"e",5), (#"f",5), (#"g",2)];
The search tree constructed is
Node(e,5,
Node(b,9,
Node(a,4, Leaf, Leaf),
Leaf),
Node(g,2,
Node(f,5, Leaf, Leaf),
Leaf))
Next, say the user requests these two
updates:
> u d 2
> u f 1
(u means "update".)
The database changes into the picture shown above that has the two Update nodes chained to the entry to the tree.
Now, a lookup of key d gives 2, a lookup of f gives 1, a lookup of b gives 9, etc.:
> l d
> l f
> l b
When we print the contents of the database,
> p
we see the following printout, which lists all nodes encountered on all the paths through the updated tree. (Lots of duplicates appear; think about why!)
Update(f,1,
IGNORE KEYS >= f IN LEFT SUBTREE:
Update(d,2,
IGNORE KEYS >= d IN LEFT SUBTREE:
Node(e,5,
Node(b,9,
Node(a,4,Leaf,Leaf),
Leaf),
Node(g,2,
Node(f,5,Leaf,Leaf),
Leaf)),
IGNORE KEYS <= d IN RIGHT SUBTREE:
Node(e,5,
Node(b,9,
Node(a,4,Leaf,Leaf),
Leaf),
Node(g,2,
Node(f,5,Leaf,Leaf),
Leaf))),
IGNORE KEYS <= f IN RIGHT SUBTREE:
Update(d,2,
IGNORE KEYS >= d IN LEFT SUBTREE:
Node(e,5,
Node(b,9,
Node(a,4,Leaf,Leaf),
Leaf),
Node(g,2,
Node(f,5,Leaf,Leaf),
Leaf)),
IGNORE KEYS <= d IN RIGHT SUBTREE:
Node(e,5,
Node(b,9,
Node(a,4,Leaf,Leaf),
Leaf),
Node(g,2,
Node(f,5,Leaf,Leaf),
Leaf))))
The IGNORE messages remind you about which parts of the shared tree are unreachable by lookups.
If we "commit" now to all the updates, the database gets traversed, its active pairs are supposed to be collected into the sorted list, [(#"a",4), (#"b",9), (#"d",2), (#"e",5), (#"f",1), (#"g",2)] and the list is rebuilt into a balanced search tree, as in the picture shown above. But the coding I have given you to collect the pairs into the sorted list is incorrect.
sml use "Q3.sml"; run [(#"a",4), (#"b",9), (#"e",5), (#"f",5), (#"g",2)]; u d 2 cThis example also goes wrong:
sml use "Q3.sml"; run [(#"a",4), (#"b",9), (#"e",5), (#"f",5), (#"g",2)]; u f 1 cYour job is to recode collect so that it assembles a list of key,value pairs that matches exactly the values that are found by the lookup function. That is, there are no duplicates, overridden values are discarded, and the list is sorted in ascending order of keys. It is ok to write additional "helper functions" that help collect do its job.
The tests you should do are listed in Q3testcases.txt. Copy the results of the tests into Q3tests.txt.
Important: This is a solo assignment --- it must be done by you, individually. If you had a partner for Exercise 3, I know it will be tempting to work in a pair, but you gotta do your own work to get these ideas loaded in your brain! It is certainly OK to discuss the assignment with the instructor, TA, or your colleagues, but all the coding must be typed by you alone, and all the concepts in the coding must be stored in your head so that you can reproduce them on demand.