When one encounters a massive language, like C++ or C#, for the first time, one is tempted to ask, ``Who thought up this mess?'' Indeed, to understand a programming language, one must look past piles of syntax and identify the language's structure. The principles we studied in the previous chapters let us do that.
Languages that do computation with storable values are called imperative languages, because commands (like assignment) give orders --- imperatives --- about updating storage. This chapter presents the core of an imperative language and applies the extension techniques to grow the language into a modern, object-oriented language like Java or C#.
===================================================
P : Program
D : Declaration
T : TypeTemplate
C : Command
E : Expression
L : NameExpression
N : Numeral
I : Identifier
P ::= D ; C
E ::= N | L | E1 + E2 | E1 - E2 | E1 > E2 | E1 == E2 | not E | new T
C ::= L = E | print L | C1 ; C2 | if E { C1 } else { C2 } | while E { C }
D ::= var I = E | D1 ; D2
T ::= struct (I : int)+ end | array[N] of int
L ::= I | L . I | L [ E ]
N ::= 0 | 1 | 2 | ...
I ::= alphanumeric strings beginning with a letter, not including keywords
===================================================
This is an assignment language, but the most interesting part of
modern assignment languages is how variables are declared and how
their storage is allocated.
We write
var x = 3; var z = new struct f: int; g: int end; var r = new array[4] of intto create three variable names in the program's namespace: x, which holds value 3; z, which holds a handle to a newly created struct object that holds two uninitialized ints named f and g; and r, which holds a handle to a newly created four-celled array object. Here's a picture:
Now, this next point is really important, and it is a key feature of modern imperative (object-oriented) programming: a TypeTemplate phrase is a storage-allocation template. Consider the above example one more time:
Let's constrast the above fragment,
var x = 3;
var z = new struct f: int; g: int end;
var r = new array[4] of int
to that in C and Pascal.
To obtain the same allocations
in C, one would write
===================================================
int x = 3;
struct MyStruct {int f; int g}; // you first name the allocation template;
struct MyStruct z; // then you use it to declare a struct
int[4] r // or, int r[4]
===================================================
Like our model core language at the beginning of this chapter, C (and Pascal) use type-template phrases to allocate the correct amount of storage for struct z and array r. But C and Pascal also use the type-template phrases as data-type names, that is, ''z has data type MyStruct'' and ``r has data type int[4].''
The data-type names
are used in the rest of the program to confirm that the variables
are used properly.
For example,
C's type checker will validate that this assignment is consistent
with z's and r's declarations:
z.f = r[2] + 1
but this one is not:
x = z[3] - r // this is a ``type error''
Since TypeTemplate phrases can be used as data-type names as well
as storage-allocation templates, we call them ``type templates.''
But remember: you can switch off C's type checker and then you
are using the TypeTemplate phrases for their primary use --- to
allocate storage.
Java and C# also use type templates as both data-type names and
storage-allocation templates.
The earlier example looks like this in Java/C#:
===================================================
int x = 3;
class MyStruct {int f; int g}; // you must declare the struct as a class
MyStruct z = new MyStruct(); // Why must we say, MyStruct, twice ??
int[] r = new int[4] // Why must we say, int[..] twice ??
===================================================
Notice the two questions just above? Java and C# make you use
the type template first to attach a data-type name to a variable name
and second to allocate the object that the variable names.
In Java, if you write merely,
MyStruct z;
int[] r;
then only the data-type names are attached to z and r and
no struct and no array objects are allocated.
Instead, z and r each have value nil (``no value'') in the namespace.
One might declare z and r without initial values so that the Java compiler learns their data types for future type checks (e.g., to enforce that only handles to MyStruct objects are assigned to variable z and that only handles to int arrays are assigned to variable r.)
We will not devote a lot of time in this chapter to
data-type checking with type templates, but their use
does not always go smoothly. Here is a standard problem:
===================================================
class MyStructA {int f; int g};
class MyStructB {int g; int f};
MyStructA x = new MyStructA();
MyStructB y = x // Is this allowed or not ?
// After all, the struct has exactly the required fields ?!
===================================================
Java/C# consider this example erroneous; Algol68 does not. At the end of the
chapter we study some difficult questions that arise when we use
type templates as data-type names.
The data-structure extension principle suggests that all storable values --- data structures --- should be storable as elements within all other data structures. This means we should allow arrays of arrays and structs, and structs of arrays and structs.
We apply the data-structure extension principle
with this simplication to the syntax of TypeTemplate:
===================================================
T ::= struct D end | array[N] of T | int
===================================================
That is, a struct's body can declare any possible data structure,
and an array can declare elements of any possible data structure.
Finally, we make int the starter type template.
It is often the case that, by simplifying a language's syntax,
we develop a more general-purpose language as a result.
(Of course, there is a cost to such generalization. For example, the C language is designed so that storage is a sequence of integer cells, and data structures like arrays and structs are an illusionary naming convention for a sequence of contiguous cells. This storage model lets C programs compile into simple, fast target code --- C is meant for writing device drivers, not databases.)
With the new syntax of TypeTemplate, we can write nested data structures.
Here is a struct named database that holds an int
and an array of 100 structs:
===================================================
var database = new struct var howmany = 0;
var table = new array[100] of
struct var idnum = new int;
var balance = 0
end
end;
// insert an entry:
count = database.howmany;
if not(count == 100) {
database.table[count].idnum = 999999;
database.table[count].balance = 25;
database.howmany = count + 1
}
===================================================
In the example, you should read database.table[count].idnum as ((database.table)[count]).idnum.
Say that we use C/Pascal-style semantics for this example:
the declaration of database allocates storage
for all 100 of the struct objects in table before a single
entry has been entered into the database.
Here is a picture of what the above code created:
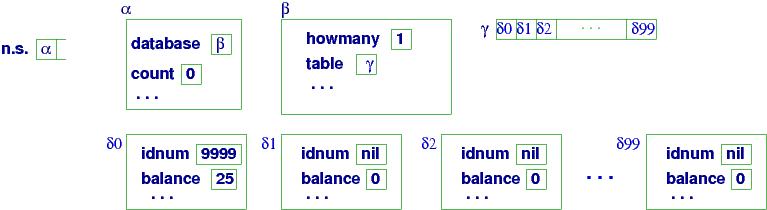
Using the diagram, we can state precisely what database.table[count].idnum denotes:
count = database.howmany;
if not(count == 100) {
item = database.table[count]; // item has value δ0
item.idnum = 999999; // δ0.idnum is assigned 999999
item.balance = 25; // δ0.balance is assigned 25
database.howmany = count + 1
}
===================================================
The diagram shows that C-style allocation allocated all the array's structs at once. But this is a waste of storage if the database is mostly empty all the time.
For this reason,
Java and C# take the opposite approach --- a nested type template
allocates only the topmost level of object.
You must use lots of new
commands to construct the objects that fill the lower levels.
This sounds strange, but programmers quickly learn to do this.
Here is the above example written in Java style:
===================================================
// this template can allocate a two-celled struct object:
class ENTRY{ int idnum; int balance = 0 }
// this template can allocate a struct that holds one int cell and 100 cells
// that can hold handles to other objects:
class DB{ int howmany = 0; ENTRY[] table = new ENTRY[100] }
DB database = new DB(); // allocates one DB object but _no_ ENTRY objects!!!
// now, insert one ENTRY object into database:
count = database.howmany;
if not(count == 100) {
ENTRY item = new ENTRY() // allocate the object only when needed !
item.idnum = 999999;
item.balance = 25;
database.table[count] = item; // store the object's handle in the array
database.howmany = count + 1
}
===================================================
Here is a diagram of what this code constructed:
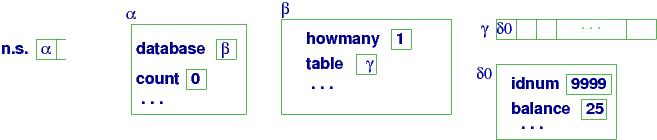
In summary, be careful if you move from C# to C (or vice versa) ---
the two languages allocate objects differently!
(If you want to do ``lazy allocation'' in C, you must use pointers
and malloc, somewhat like this:
int* r; // declares r as a pointer
int howmany = 100 // number of array elements desired
// save in r the address of a 100-celled array:
r = (int*)(malloc(howmany * sizeof(int)));
// assign 99 to cell 0 of the array:
r*[0] = 99
)
Languages like Python and Ruby let you "declare" and allocate a nested data structure
one layer at a time. We can do this in our core language, by changing
the syntax of TypeTemplate like this:
T ::= struct D end | array[N] | int
Now, array[N] allocates an N-element array object whose cells
all hold nil. Later, we fill in the structures within
the array.
The database example would get rewritten like this, which is a style
halfway between the previous two examples:
===================================================
var database = new struct var howmany = 0;
var table = new array[100]
end;
// insert an entry:
if not(database.howmany == 100) {
database.table[howmany] = new struct var idnum = 999999;
var balance = 25
end;
database.howmany = database.howmany + 1
}
===================================================
The result would be the same storage layout that we saw in the
previous diagram.
This setup will let us insert values of different type templates
into the same array, e.g., we can say next
database.table[howmany] = new array[2]
mixing structs with arrays in the same array. Perhaps you like this;
if not, you add type checking like Java's.
=================================================== E: Expresssion N: Numeral D: Declaration T: TypeTemplate I: Identifier E ::= N | ... | new T D ::= var I = E | D1 ; D2 T ::= struct D end | array[N] of T | int ===================================================To recap:
Exercises:
C ::= . . . | C1 ; C2 | if E { C1 } else { C2 } | while E { C }
The Declaration domain uses the sequencing control
structure, ;, which is important because
declarations
can be initialized like this:
int x = 2; int y = x * xThe order of the declarations, stated by ;, matters.
Since the language has arrays, it is
useful to introduce a control structure that lets us
``iterate'' (process) an array's elements.
Perhaps we add a for-loop, which counts upwards
from some lower bound to some upper bound by ones:
C ::= ... | for I = E1 upto E2 : C
Within the for-loop, variable I is used as an index for
locating elements in an array, e.g.,
var evens = new array[9];
for index = 0 upto 8:
evens[index] = index * 2
Does a struct require a control structure for ``iteration''?
If we wanted one, it might look like this:
C ::= ... | for I in fieldsOf L : C
The loop would look up each field in struct L
which would be used to index L's fields. Here is an example:
var evens = new struct var a = 0;
var b = 2;
var c = 4
end;
var sum = 0;
for k in fieldsOf evens :
sum = sum + evens.k ;
===================================================
D ::= var I = E | D1 ; D2 | proc I() { C }
C ::= L = E | C1 ; C2 | ... | L()
T ::= int | struct D end | array[E] of T
E ::= N | ... | new T
L ::= I | L . I | L [ E ]
===================================================
The definition construction is proc I(){C} and the calling construction
is L().
The syntax for structs, seen above, exposes an important idea --- we can
embed procedures within a struct.
This insight led to the development of object-oriented
programming as first seen in the Simula67 programming
language --- objects are structs that contain both procedures
and variables. Here is an example:
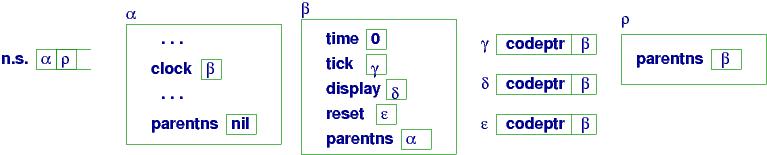
var clock = new struct var time = 0;
proc tick(){ time = time + 1 };
proc display(){ print time };
proc reset(){ time = 0 }
end
The procedures inside clock maintain variable, time.
We use clock like this:
clock.tick();
clock.tick();
clock.display()
Here is a diagram of storage after clock is declared and
the previous calls are finished:
The picture shows that the clock object is implemented as a namespace,
where tick, reset, and display are names of closure objects.
When one calls clock.tick(), the following happens:
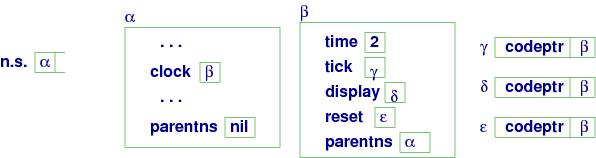
This example shows that
===================================================
D ::= var I = E | D1 ; D2 | proc I() { C } | class I = T
T ::= int | struct D end | array[E] of T | L
===================================================
Note that the L in the BNF rule for T is the construction that
calls a named class.
Here is how we might use a class to declare the database seen earlier:
===================================================
class Entry = struct var idnum = new int;
var balance = 0
end;
class DB = struct var howmany = 0;
var table = new array[100] of Entry
end;
var database = new DB
===================================================
The classes divide the definition into
readable substructures.
Java people say that
variable database ``denotes an object of class DB'' or
``database has type DB.''
But classes are not, strictly speaking, data types, even though
Java lets a programmer think they are.
Please remember what classes (and TypeTemplate phrases) really are: A class is a storage-allocation template. When we define a class, we define an allocation template, and when we use the keyword, new, we activate the template to allocate storage. The Java compiler tries to use the class names as data types, but this can lead to trouble, as we see at the end of this chapter.
This development shows that a core assignment language with structs already has the computational power to do object-oriented programming --- it is merely a matter of introducing a couple of key abstracts (command abstracts and type-template abstracts) for convenience.
=================================================== D ::= var I = E | D1 ; D2 | ... | module I = D | import L ===================================================A module differs from a class because a called module activates a set of declarations at the point where it is imported (called); the importation ``links'' the module's declarations to the program. In contrast, a class is called to allocate storage.
Here is an example to make this point:
===================================================
module M =
var x = new int;
class C = struct var a = 0 end;
var y = new array[10] of C;
proc initialize(){
x = 0;
for i = 0 upto 9 { y[i].a = i }
}
// The above code often resides in a separate file, named M.
import M; // activates and links M's declarations to this program
initialize() // calls the proc as if it were declared in the program
var z = new C; // class C is used as if it were declared in the program
z.a = x + y[0].a
===================================================
Once M is imported, its declarations are
linked to the program as if they had been written there in the first place.
Since module importation is a kind of linking, does it make sense
to ``import'' twice? That is, can we do this?
import M;
import M
and is it the same as importing M just once?
Most languages ignore repeated imports of the same module.
Here is another question: Should we allow this example?
===================================================
module M = var x = 7;
module N = var x = 99;
import M;
import N;
x = x + 1 // which variable x is updated?
===================================================
This is a serious issue when a large program is assembled from
many modules that are linked together --- there is always a chance that
two distinct modules declare the same name. For this reason,
most languages require
that a module's names are referenced
with dot notation, like this:
===================================================
module M = newstruct var x = 7 end; // might be in a separate file
module N = newstruct var x = 99 end; // might be in a separate file
import M;
import N;
N.x = M.x + 1
===================================================
Languages that use modules-as-structs often add an operation
that ``opens'' the module so that the declarations are exposed
like we saw them in the first place:
module M = newstruct var x = 7 end;
from M import *; // import * means that all declarations in M are linked
// as if they were declared in the program.
x = x + 1
A variation of this operation opens the module for a limited scope:
module M = newstruct var x = 7 end;
module N = newstruct var x = 99 end;
import M;
import N;
with M do {
N.x = x + 1 // inside the with M do, references to x mean M.x
}
In the previous chapter we learned how to add
parameters to abstracts. These same techniques are useful
for adding parameters to classes and modules.
Here is an example of a parameterized class:
===================================================
class Entry = struct var idnum = new int;
var balance = 0
end;
class DB(size) = struct var howmany = 0;
var table = new array[size] of Entry
end;
var database = new DB(100)
===================================================
The parameter, size, lets us adjust the size of a new database.
Many object-oriented languages transmit the argument to a class's constructor
method and not to the class itself:
Here's how the above example looks in Java:
class Entry { int idnum; int balance = 0 }
class DB {
int howmany = 0;
Entry[] table;
DB(int size) {
table = new Entry[size]
}
}
DB database = new DB(100);
Modules might also be parameterized, perhaps by expressions
or even type-templates.
Consider this example, which defines
a database module parameterized on an int and the type-template format to be
stored in the database table:
===================================================
module DataBase(size, recordTemplate) =
var howmany = 0;
var table = new array[size] of recordTemplate;
proc initialize(){
for i = 0 upto size - 1 {
table[i].init() } // oops -- how do we know recordTemplate contains proc init ?
};
proc find(index):
if index >= 0 and index < size {
answer = table[index].getVal() // how do we know recordTemplate contains function getVal ?
return answer
}
===================================================
If we had this class,
===================================================
class Entry = struct var idnum = new int;
var balance = new int;
proc init(){
idnum = -1;
balance = 0
};
fun getVal(){ return balance }
end;
===================================================
we could activate (import) the module like this:
Database(100, Entry)
This allocates storage for howmany and table, where
the latter is an array of 100 Entry structs.
The coding of DataBase is suspect --- it assumes that whatever the recordTemplate type-template might be, it includes a procedure named init and a function named getVal. To ensure the security of module Database, we should annotate its parameters with these requirements. The data-type-like annotations are called an interface.
Here is a Java-like coding of the interface that we want:
===================================================
interface RecordInterface = struct init: void -> void;
getVal: void -> int
end;
module DataBase(size: int, recordTemplate: RecordInterface) = ... like before ...
===================================================
The interface gives enough information that the programmer
or compiler can check that the module is coded sensibly.
The annotation of size ensures that an int argument will be bound to it,
and the annotation of recordTemplate ensures that a struct object
with at least an init procedure and a getVal function will be bound to it.
The type-template argument that is bound to
parameter recordTemplate must match the interface; it must
``implement'' it, as one says in Java-speak:
Database(100, Entry) // Entry implements (matches) RecordInterface
In a similar way, we can use interfaces for module arguments to modules,
to enfore correct linking:
===================================================
interface DataBaseInt = { howmany: int;
initialize: void -> void;
find: int -> int
};
module System(db: DataBaseInt) = // db binds to a declaration that holds the
// identifiers listed in DataBaseInt
var current = new int;
var value = new int;
db.initialize();
current = db.howmany - 1;
value = db.find(current)
;
. . .
import System(import Database(100, Entry)); // link Database to System
===================================================
Features like these are found in the module-oriented languages,
Modula2 and Ada.
Here is the syntax of declaration blocks and type-template blocks:
===================================================
D ::= var I = E | D1 ; D2 | class I = T | module I = D | import L | begin D1 in D2 end
T ::= int | struct D end | array[E] of T | L | begin D in T end
===================================================
Returning to the database example, we can improve the definitions
so that the variables owned by the database are made private:
===================================================
class Entry = struct var idnum = -1;
var balance = 0
end;
class DB(size) = struct
begin var howmany = 0 // these two declarations are private
var table = new array[size] of Entry // to the struct
in
proc find(i){ ...table[i].balance()... }
proc update(i,...){ ...table[i] ... howmany ... }
end end;
module DataBase(max) = begin var mybase = new DB(max) // this declaration is private
in
proc searchDataBase(...):
...mybase.find(...)...
proc processDataBase(...):
...mybase.update(...)...
// but we cannot reference mybase.howmany
// nor mybase.table
end;
import DataBase(100);
DataBase.searchDataBase(...);
DataBase.processDataBase(...)
// but we cannot reference Database.mybase
===================================================
The example shows how protection was placed
around private variables howmany and table within DB so that
once a DB object is allocated, all uses of the two variables must
be made via the public procedures, find and update.
The same idea is used to protect the struct, mybase, within
module DataBase.
Of course, in C# and Java, the keyword, private, is used to label a declaration as local to a block.
The qualification principle makes it possible to encapsulate declarations within components so they are safe from unauthorized use, no matter where the component is inserted into a system. Large systems building is possible only because of the qualification principle.
Two distinctive features of object-oriented languages are subclasses and virtual methods. These concepts are surprisingly complex, yet their correct use is critical to successful object-oriented programming.
Let's review subclasses with a small example from Java.
Here is a class named Point:
===================================================
class Point {
int x; int y;
Point(int initx, int inity) { // constructor method
x = initx; y = inity
}
void paint() {
System.paintPixel(x,y,255,255,255) // paints a white pixel at x,y
}
boolean equals(Point q) { // compares this point to point q
return x == q.x & y == q.y
}
}
===================================================
The class, which might reside within a graphics framework,
defines two fields and a method that paints the point and
a method that compares an object
constructed from this class to another that has the structure
of a Point, for example:
Point p1 = new Point(0,0);
Point p2 = new Point(1,1);
p1.paint(); p2.paint();
boolean b = p1.equals(p2); // will compute to False
The graphics framework might also deal with color, so there is
the notion of a colored point, which is a graphics point (pixel),
colored with RGB (red-green-blue) coding:
===================================================
class ColoredPoint extends Point {
int[] color;
ColoredPoint(initx, inity, initr, initg, initb) {
super(initx, inity);
color = new int[3];
color[0] = initr; color[1] = initg; color[2] = initb
}
void paint() {
System.paintPixel(super.x, super.y, color[0], color[1], color[2])
}
boolean equals(ColoredPoint q) {
return super.equals(q) &&
color[0] == q.color[0] &&
color[1] == q.color[1] &&
color[2] == q.color[2]
}
}
===================================================
A ColoredPoint builds on the structure of a Point, adding
a data structure that remembers RGB-values. For this reason,
its paint method is rewritten so that it uses a point's location
as well as its color.
The recoding of paint is called a method override,
because there is already a coding in the superclass but we are
overriding it with a new coding. Method override is a key technique
used in graphics libraries written in object-oriented style: a graphics
widget, say a Button, is coded with simplistic paint and interrupt
handling methods, which the programmer later overrides with more
detailed ones.
Notice how the coding in ColoredPoint can obtain the values of x and y in Point with the label, super.
In the above example, to compare one colored-point object equal to another, we must also change equals: we must check that the x,y coordinates are identical (this is done with a call to super.equals --- the equals method in the super class, Point) as well as the RGB integers are equal.
Here are examples of Java points and colored points:
===================================================
Point a = new Point(0,0); // at position 0,0 --- the upper left corner
ColoredPoint b = new Point(0,0, 255, 0, 100); // violet
ColoredPoint c = new Point(0,0, 255, 0, 0); // red
a.paint(); // paints a white point at 0,0 -- uses paint in class Point
b.paint(); // paints a violet point at 0,0 -- uses paint in class ColoredPoint
a.equals(b); // calls equals in Point; returns True
b.equals(c); // calls equals in ColoredPoint; returns False
b.equals(a) // calls equals in Point(!); returns True
===================================================
The call, a.equals(b), uses the equals method attached to object
a, a Point object, to see if object b has the same x,y coordinates;
the color information in b does not matter --- from the perspective
of a, b is ``equal'' to it.
The call, b.equals(c), uses b's equals method, within ColoredPoint, to compare b's position and color to c's. Finally, the third call, b.equals(a), is surprising, since b's equals method, expects a ColoredPoint argument. Actually, b possesses two equals methods --- one for comparing itself to ColoredPoint objects and one for comparing itself to Point objects. Here, the latter is used to force an equality comparison between a and c. Is this what you expected? Is it what you want? Why did it happen?
The answer is that objects are structs, and a subclass, like ColoredPoint,
defines a struct type template that is the Point struct appended
to the ColoredPoint struct. It is as if
class ColoredPoint defines this
type template:
{ int x; int y;
void paint() { ... } // this method will never be used (!)
boolean equals(Point q) { ... }
int[] color = ...;
void paint() { ... } // this newer method is always used
boolean equals(ColoredPoint q) { ... }
}
and object b contains exactly these fields.
The first occurrence of method paint is overridden
by the second.
The name, equals, is overloaded, because it has
two ``bodies'', which are chosen based on the data type (pattern)
of argument that is used when equals is called.
Stated more precisely, when a call like b.paint() or b.equals(c) occurs, the fields of object b are searched from newest to oldest (``last to first,'' in the above coding) until there is a match of a method name and its parameter types to the call. This is how b.equals(a) executes the variant, boolean equals(Point q).
If you can understand the above story, congratulations! But the
explanation is a complicated mess. Let's start over.
Returning to our core
imperative language, we get subclasses like this:
first, we add an append operation, +,
to the syntax of type templates:
===================================================
T ::= int | struct D end | ... | T1 + T2
===================================================
This lets us code structs in stages:
var p = new (struct
var x = new int;
var y = new int;
end
+
struct
color = new array[3] of intecell
end)
p.x = 0;
p.color[1] = 255
The above example does not seem to add much,
but once we add class names (and procedures/methods), it gets interesting:
===================================================
class Point = struct
var x = new int;
var y = new int;
proc paint() { ...x...y... }
end;
class Color = struct
var color = new array[3] of int;
proc paint() { ... super.x ... super.y ... color ... }
end;
class ColoredPoint = Point + Color; // aha!
var p = new ColoredPoint; // allocates a struct with all the fields (``attributes'')
// of Point and also Color
p.x = 0;
p.color[1] = 255
===================================================
Some object-oriented languages use classes exactly
as shown here. (The class-fragments are called mix-ins.)
The mainstream object-oriented languages (e.g., Java) allow only an ``incremental'' append, where a ``base class'' is ``extended.'' ColoredPoint is a subclass of Point because it builds on Point --- it has all Point's fields and then some. Subclassing is an abbreviation for appending structs.
To understand the complex Java example shown earlier, we should
look at a storage-layout picture.
Here is a simplified version of the example (just method overrides,
no overloads):
class Point = struct
var x = new int;
var y = new int
proc paint() { ...x...y... }
end;
class Color = struct
var color = new array[3] of int;
proc paint() { ... super.x ... super.y ... color ... }
end;
class ColoredPoint = Point + Color;
var a = new Point;
var b = new ColoredPoint;
Variable a names an object in the heap; so does b, but the latter's
object is broken into two namespaces, since it is built in two steps.
Here is the picture of the storage layout:
We see that the global names are saved in namespace α.
When a was declared, the object at
heap address ε is allocated, based on the coding named
Point.
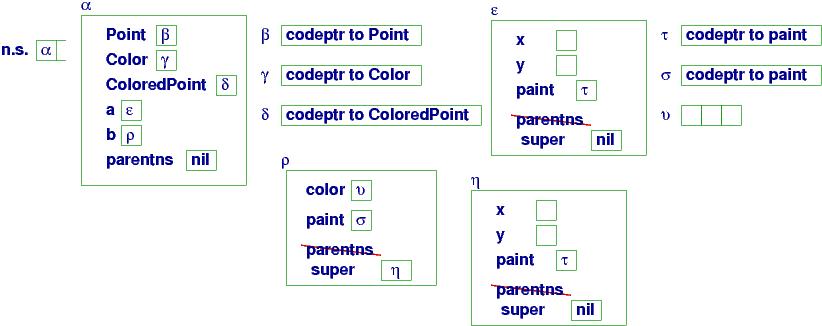
There is a difference in the picture from the previous ones --- in object ε, notice that method paint, which names the procedure code stored at location τ, does not save an address of where to find global variables. So, we now have dynamic scoping, as we will see.
When b is declared, an object, ρ, holding the namespace of Color, is allocated. It is linked to the object, η, that holds the namespace of a Point. The link, which we used to call parentns, is now called super. This is why we can write super.x and super.y in the coding of method paint within class Color --- super is the name of the link to the ``super object.'' If we write super.x, we force the use of variable x in the superclass even if there is a variable x that is more local. This is how you see super used most often in Java.
Now, say that we do this method call:
b.paint()
Since the active namespace is α, the name b means ρ ---
the call is ρ.paint. A new namespace is allocated:
The parentns link, which leads us to paint's nonlocal variables
is set to the address of the object named in the method call,
b.paint(). This address is also called self or this in some languages.
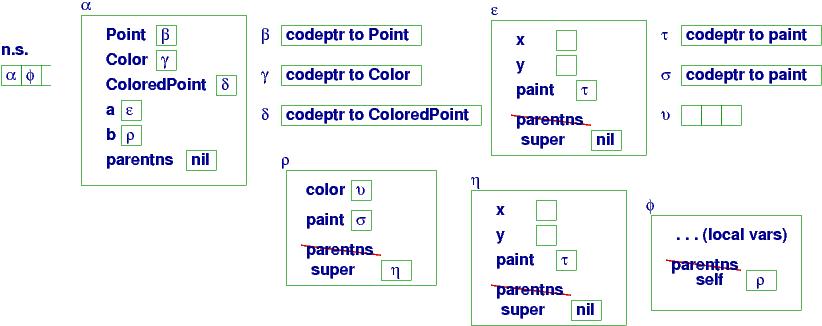
Say that the coding of paint mentions self.x and say that the call b.paint() executes. You can see from the diagram that the search for self.x looks in namespace φ to learn that self means ρ. So, the search for ρ.x looks in namespace ρ for x and proceeds to namespace η before x is found in the ``currently called object.'')
Since paint's self link is set only when paint is called, the link can be different for different calls of paint --- it is dynamic scoping. This leads to surprising consequences, as we see in the next section.
From Smalltalk onwards, object-oriented languages allow objects to have multiple fields named the same. Whenever we reference one of the object's fields, there is a sequential (dynamic) lookup, starting from the ``newest'' (subclass) fields towards the ``oldest'' (superclass) fields.
We saw this with the paint methods in the earlier
example. Here is a second example, coded in Java:
===================================================
class Point {
int x; int y;
...
string toString()
{ return "Point: " + x + "," + y }
}
class ColoredPoint extends Point {
int[] color;
...
string toString() {
return "ColoredPoint: " + super.x + "," + super.y
+ "; colors: " + color[0] + "," + color[1] + "," + color[2] }
}
Point a = new Point(0,0); // at position 0,0 --- the upper left corner
ColoredPoint b = new Point(0,0, 255, 0, 100); // violet
System.out.println(a.toString()); // prints "Point: 0,0"
System.out.println(b.toString()); // prints "ColoredPoint: 0,0; colors: 255,0,100"
===================================================
When ColoredPoint object b is constructed, it has two fields named
toString, but for the call,
b.toString(), dynamic lookup always locates
first and executes
the newer version of toString within b, namely the one from
class ColoredPoint. In this way, the older method
is overridden --- cancelled -- by the newer one.
In practice, overriding can be very useful, especially when you
are linking your own subclasses to prewritten
superclasses embedded within a
framework. (This is how most GUIs are written, with frameworks.)
So far, so good! But strange things can happen with dynamic lookup.
Here is the point-coloredpoint example again, rewritten to remove
super.equals and rewritten so that whenever a colored point
is compared to an ordinary (noncolored) point for equality,
the result is false:
===================================================
class Point {
int x; int y;
Point(int initx, int inity) { // constructor method
x = initx; y = inity
}
boolean equals(Point q) {
return x == q.x && y == q.y
}
boolean hasSameCoordinates(Point q) {
return equals(q)
}
}
class ColoredPoint extends Point {
int[] color;
ColoredPoint(initx, inity, initr, initg, initb) {
super(initx, inity);
color = new int[3];
color[0] = initr; color[1] = initg; color[2] = initb
}
boolean equals(Point q) {
if (q instanceof ColoredPoint)
{ return hasSameCoordinates(q) &&
color[0] == q.color[0] &&
color[1] == q.color[1] &&
color[2] == q.color[2]
}
else { return false } // all Points are nonequal to ColoredPoints
}
}
===================================================
We coded ColoredPoint so that its equals method overrides
the equals method of Point, meaning that the latter is never
used within a ColoredPoint object. We eliminated super.equals
by calling a stand-in method, hasSameCoordinates,
which is meant to check the equality of the x,y coordinates of two
points. But our coding will go horribly wrong:
===================================================
Point a = new Point(0,0);
ColoredPoint b = new Point(0,0, 255, 0, 100);
a.hasSameCoordinates(b); // calls hasSameCoordinates in Point, which
// calls equals in Point, which returns true
b.equals(a) // calls equals in ColoredPoint, which returns false
a.equals(b); // calls equals in Point(!) which returns true (?!)
b.hasSameCoordinates(a); // calls hasSameCoordinates in Point, which
// calls equals in ColoredPoint(!),
// which returns false (!!)
b.equals(b); // calls equals in ColoredPoint, which
// calls hasSameCoordinates in Point, which
// calls equals in ColoredPoint(!!), which
// calls hasSameCoordinates in Point, which
// calls equals in ColoredPoint, which ... repeats forever )-:
===================================================
Almost nothing goes correctly, thanks to dynamic lookup!
The problem is that the coding of
hasSameCoordinates must call the coding of equals
within class Point to work correctly.
This is destroyed by dynamic method lookup --- what we see in the
coding of class Point has no relationship to what the computer does.
How can we write programs in a language that we cannot trust
with our own eyes?
In this situation, we must draw the storage layout and trace the use of the parentns (super and self) linkages.
Imperative languages are for updating storage in small, baby steps. Perhaps the storage is one big piece of primary memory, with millions of small cells, or perhaps the storage is split into hundreds of objects, each with its own location and each holding just a few cells, or perhaps the storage is the grid of RGB-pixels that lights up your computer's display. In any case, if the computation requires locating a cell in a storage structure, reading it, and changing it, then you will be using an imperative language to do it.
In the chapters that follow, we consider other views of computation.