Copyright © 2010 David Schmidt
Chapter 4:
Control- and data-structure extensions
- 4.1 Data-structures
- 4.1.1 Semantics of data structures
- 4.1.2 Data-structure extension
- 4.2 Control-structures and extension
- 4.3 Combining control and data: Iterators
- 4.3.1 Map, filter, and reduce
- 4.4 Summary
Once a language's characteristic domains and their operations
are fixed, the language's computational abilities are largely
decided. But there is now the matter of convenience --- how easy
is it to organize data and to control the order of operations on it?
A language should provide data structures and
control structures to make it easy to program.
The purpose of this chapter is to introduce two language-extension
principles for adding data structures and control structures to
a core language.
4.1 Data-structures
A language should provide data structures, that is,
``containers'' that hold multiple values. Lists, arrays,
record structs (structures), hash tables, stacks, trees, etc.,
are examples. A typical language provides one or a few such
structures, and a programmer is expected to be expert at simulating
other structures in terms of the built-in ones.
Data structures might appear within any of the language's characteristic
domains. Consider an array, for example:
-
an array is an expressible value if the language lets you write
an arithmetic expression that denotes the entire array
(e.g., in Python you can write r = [2,3,5,7,11], expressing
a five-integer array)
-
an array is a denotable value if the language lets you declare (name) an
array (e.g., in Java, int[] r names int array r)
-
an array is a storable value if the language
and lets you store an entire array all at once into storage
(You do this in Java with an initialization like
int[5] r = {2,3,5,7,11}. But remember that the subsequent
assignment, int[] s = r stores the handle for an array
into s and not a new array --- r and s name the same array!)
In Fortran-like languages, arrays are denotable (``declarable'') but
not expressible and not storable.
(Instead, you express and store the array's elements, one by one.)
An object-oriented language might use an array as an expressible,
denotable, and a storable value.
Any data structure must have operations for constructing
a new instance, perhaps with starting elements, inserting
values into it or updating the values already there,
and extracting (indexing, referencing) the
values within it.
Insertion and extraction are often done with the aid of indexes or keys.
Here are common techniques for indexing:
-
numerical indexing, as used in arrays, e.g., a[2], which
references the element in array a numbered by 2
-
identifier (key) indexing, as used with structs and hash tables,
e.g., table["horace"] or table.horace
references the value indexed by
string/name horace in table.
-
structural indexing, as used with stacks and trees, e.g.,
stack.top() or head(stack) use the operator names, top and
head, to reference
the front value in stack.
Here is a short list of commonly used data structures:
-
array: a sequence of elements, indexed by nonnegative integers,
updated by assignment using integer indexes. Often a fixed length
and cannot grow. Often, all the elements must be of the same
data structure, e.g., all ints or all chars or all int arrays.
Standard examples of operations go
int[] r = {2, 3, 5, 7, 11} // declaration and initialization merged
print r[x + 1] // reference
r[x + 1] = r[x] + 1 // update
Sometimes, the array is allowed to grow, e.g.,
r.append(13). There might be additional operations for
searching, sorting, etc.
-
list: a sequence of elements, indexed by head (front elements),
tail (rest of the sequence), and assembled by cons (appends
an element to the front of the list).
Sometimes indexing by
nonnegative ints is allowed. Often allowed to grow, with the use of
an append operator.
Also, the elements can be values and structures of different forms,
e.g., a list that holds an int, a string, and another list.
mylist = ["two", 3, [5,7]] # initialization
print head(mylist) # prints twp
newlist = cons(2, tail(mylist)) # assembles [2,3,[5,7]]
newlist.append(11) # updates newlist to [2,3,[5,7],11]
There might also be operations for appending two lists or
referencing a sublist, e.g., in Python, one can write
flatlist = mylist[:2] + mylist[3] # assembles ["two",3] + [5,7] == ["two",3,5,7]
-
struct: a finite set of elements, indexed by names, updated
by assignment to its elements. A C-like example looks like this
struct x: { int a;
int[100] b;
} // the indexes for struct x are a and b
x.a = 11;
x.b[99] = x.a + 12;
print x.b[99] // prints 23
The two declarations within x are called its fields.
Once declared, a struct cannot grow in size.
-
hash table: a struct that can grow in size, found in scripting
languages like Perl and Python:
hash = {"a": 11; "b": [2,3,5,7]} # constructs and initializes the table
# the keys are strings, "a" and "b"
print hash["a"] # prints 11 if "a" has an entry in table,
# else it crashes
if "c" in hash : # the expression, KEY in TABLE, asks if KEY is present
print hash["c"]
hash["c"] = "abc" # extends the table with an entry for key "c"
hash["a"] = 0 # updates "a"'s entry
Usually, there is no restriction on the value or structures placed
within the hash table.
-
immutable sequences: sequences of characters (``strings'') or numbers
or other values. Can be
indexed like an array but once created, their elements cannot be altered.
Are used because they have a small
representation in storage and can be shared (because once created,
they never change).
Come with a rich collection of operations for lookup, assembly, and sorting.
An example:
myname = "horace"
yourname = "horace" # the variables share (the location of) the string
myname = myname[3:] # myname gets (the location of) substring "ace";
# the string, "horace" rests unaltered in storage
print yourname # prints "horace"
indexnum = yourname.find("ac") # assigns 3 to indexnum
-
inductively defined structures, where grammar equations as used
to define the data structure and its constructor operations.
Here is an example binary-tree data structure, bintree, whose
nodes and leaves hold ints, defined as
one might in ML, Haskell, or Ocaml:
datatype bintree = leaf of int | node of int * bintree * bintree
val mytree = node(1, leaf(2), node(3, leaf(4), leaf(5)))
fun printTree(t) =
if t is node(n,left,right):
printTree(left)
print n
printTree(right)
elif t is leaf(m):
print m
printTree(mytree) // prints 2 1 4 3 5
Sometimes the grammar equation defines parameter patterns that can
be used in function definitions, e.g.,
fun printTree(leaf n) = print n
| printTree(node(n, left, right) =
printTree(left); print n; printTree(right)
Inductively defined structures are usually immutable, that is,
once constructed, they never change. If you want to ``change''
an immutable structure, you are stuck rebuilding a copy of the
original
structure where you insert the new value in place of the original.
For example, here is a function that replaces all occurrences
of integers at the leaves of a bintree by -1:
fun eraseLeaves(t) =
if t is node(n,left,right):
answer = node(n, eraseLeaves(left), eraseLeaves(right))
elif t is leaf(m):
answer = leaf(-1)
return answer
mytree = eraseLeaves(mytree)
Function eraseLeaves constructs a new bintree from the ints
and structure embedded in the original mytree. The new tree
is assigned to variable mytree. The original tree remains in
heap storage but is orphaned --- it has no name. Later, a
garbage collector program will examine heap storage and
deallocate all orphaned objects, including this one.
4.1.1 Semantics of data structures
In an earlier chapter, we studied the interpreter-coded semantics
of an imperative C-like language and the semantics of an object language.
In the former, memory is a long sequence of cells. In the latter,
a heap holds distinct objects.
Adding data structures to the memory used for C is a bother, because
the data structure must be ``flattened'' into a long sequence of cells
so that it matches the memory. For example, say that a C-like program
declares and initializes these variables:
int x = 7;
int[4] y = [1,2,3,4];
int[2][3] z = [[00,01,02],[10,11,12]];
The interpreter
configuration for the program would look like this:
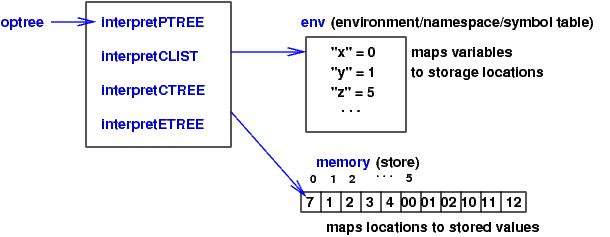
Notice that the storage location associated with array y is 1,
the address of the array's first element.
Hence, an expression like y[x-4] computes to storage location 1 + (7-4) = 4.
Array-indexing errors are detected only if the C-compiler inserts
extra program instructions that explicitly check that x-4 >= 0 and
x-4 < 4 for the bounds of array y.
In a similar way, the matrix z is flattened into a sequence of
two rows, each row owning three elements.
If we add structs to this interpreter, the fields of the struct
must also be flattened to fit memory, and the C-compiler must
translate the field lookups into integer indexes.
In contrast, it is simple to add arrays to the interpreter for the
object language --- an array is just an object. Here is a picture
of the above three declarations as configured in an object interpreter:
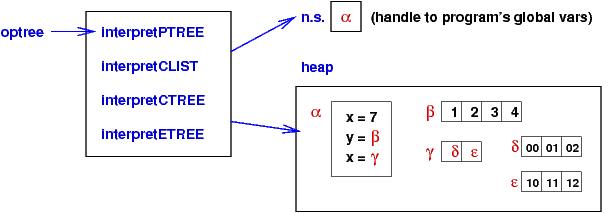
Here, a linear array is a self-contained object, and a matrix
is a linear array of handles to linear arrays.
Exercise:Extend one of the interpreters, either the
one for C-like languages or the one for object languages, to process
multidimensional arrays. Alternatively, add structs to either
interpreter. (This will take some effort for the C-like interpreter.)
Finally, if you have accomplished both steps, allow arrays to hold
structs and structs to hold arrays.
4.1.2 Data-structure extension
What can one place in a data structure? Should there be
restrictions? For example, an immutable string is a sequence
of characters --- you build a string out of characters,
not out of hash tables or trees. What about arrays?
Can an array hold only ints or can it be an array of arrays?
When exploring the range of use of data structures, a language
designer can exploit the
data-structure extension principle:
-
Every kind of data structure may be used as elements for another
kind of data structure; that is, data structures may be nested.
For example, if a language supports both arrays and hash-tables,
then the data-structure extension principle states that the language
should also support arrays of hash tables, arrays of arrays,
hash tables that hold arrays and hash tables that hold hash tables.
In this way, the full power of the data structures become available.
Here is a simple example:
If we apply the data-structure extension
principle, then we allow arrays to hold other arrays. We
express this freedom in the grammar rule for Declarations for
a C-like language:
D : Declaration
T : TypeStructure
D ::= T I | D1 ; D2
T ::= int | int* | T[N]
The new syntax domain, TypeStructure, defines the types of
data structures supported in the language. An array
of array (a matrix) of pointers to ints would be declared like this:
int*[3][4] r
because int* is a type structure (the ``int pointers''),
then so is int*[3], then
so is int*[3][4]. Another example is int[3]** (a pointer to a pointer
to an array of three ints) and int**[3} (what is it?).
Here is an example of an Algol/ Pascal-like language, where structs, arrays,
integers, and pointer variables can be combined:
D : Declaration
T : TypeStructure
D ::= var I : T | D1 ; D2
T ::= int | array[N1..N2] of T | struct D end | ptrTo T
Perhaps you never considered this, but BNF rule clearly shows that
a ``struct'' (record)
defines a collection of variable declarations.
For example,
var s : struct f: int; g: array[2..4] of int end
declares variables f and g, collected under the struct name, s.
We access the variables by dot-notation, e.g.,
s.f = 2; s.g[1] = s.f
We saw in the previous chapter that the semantics of a struct/object
is a namespace. We will see in the next chapter that a module
is also like a struct, in that its semantics is a namespace.
The BNF rule for declarations shows which data structures are denotable.
We consult the BNF rule for expressions to see which data structures
are expressible. Consider again ints, arrays, pointers, and structs:
For example, 4 is an int-expression,
and {2,3,5,7,11} is an int-array expression.
How do you express a pointer to an int?
Can you express a struct? Can you do this in C? In Python?
(Python uses dictionaries rather than structs.)
Finally, you must look at the BNF rule for commands to see how
data structures are stored into memory. (Look at the assignment
construction as well as any writeData or writeFile instructions.)
Warning: it is not always the case that every value that is expressible
is also storable! (The syntax of assignment, L = E, can be
a bit misleading --- you must study the semantics definition of
assignment to learn if there are any restrictions on forms of E
that can be assigned.)
4.2 Control-structures and extension
A language provides control structures
for ordering or organizing multiple operations.
For example, if a program contains two assignment commands,
then a control structure orders
the commands so that the order the commands perform is clear.
Common forms of control structures include
-
sequencing, which makes one operation start and finish before
another can commence
-
choice, which chooses one operation from a collection;
the choice can be made by evaluating one or more true-false
conditions. If- and case-commands are examples.
-
repetition, which performs an operation over and over until some
completion condition is achieved. While, repeat, and for-loops are examples.
-
parallel, which performs multiple operations at the same time.
-
break, return, raise, or goto, which abandons
the usual control and reset it to another point in the program's
syntactic structure.
An important and often-neglected question is this: Which
characteristic domains can be controlled?
For example, it is common to have control structures that control
computation on storable values, that is, control the order of commands
that update storage and buffers
(e.g., assignments, input/output).
But many languages let you control computation on expressible values
(expressions).
For example, in C, one can choose which value to assign to variable
x's location like this:
x = b ? e1 : e2
where b is the condition whose value determines whether
e1's or e2's value is assigned to x.
In Python, there is also a conditional expression that looks like this:
x = e1 if b else e2
where e1 is the ``usual value'' assigned to x and e2 is the
``exceptional'' (rarely used) value.
Although we do not consciously think of it, there is usually
a control structure that orders how functions, modules, variables, etc.,
are declared. This can be important for determining, say, the order
in which one module imports other modules in a large system.
If a language has control structures,
there is the
Control-structure extension principle:
-
Every syntactic domain may be extended by control structures.
For example, say that the domain of commands looks like this:
C ::= L = E | C1 ; C2 | if E { C1 } else { C2 } | while E { C } | print E
There are three control structures here: sequencing, C1;C2,
conditional, if, and repetition, while.
We can extract these and consider the structure of control:
K ::= P | K1 ; K2 | if E { K1 } else { K2 } | while E { K }
where P represents the operations of the underlying syntax domain
(e.g., assignment and print in the above example).
But we might also add control to, say, expressions or declarations.
Consider declarations with control structure:
===================================================
D ::= T I | D1 ; D2 | if E { D1 } else { D2 } | while E { D }
===================================================
Are these sensible? Yes --- it makes perfect sense to sequence
one declaration before another, so that the second might reference
the structures defined in the first (D1;D2). Also, based on
some starting input values, perhaps a programmer might choose
to declare data structures appropriate to the input values,
and conditional control would be used. (This is useful to
macroprogramming and generative programming.)
Finally, iteration might
be used to declare a family of related
data structures.
Although it is not realistic to demand all control structures
for all syntax domains of a language, a language user should search
their chosen language to see which control structures are available
and a language designer should carefully consider inserting
such structures at the various levels of the language.
4.3 Combining control and data: Iterators
As noted at the beginning of this chapter, each form of data structure
comes with operations for construction, retrieval, and updating.
Now that we have examined both data and control structures, we note
that a data structure often comes with control structures
for examining and processing all its elements.
For example, we know that an element of an array can be
referenced with an integer index (e.g, print r[3])
and can be updated by means of an index with an assignment
(e.g., r[3] = 99.) But it is also standard to process
all the elements of an array with a loop. For this reason,
an array might come with its own form of loop for processing
its elements.
A first form of loop customized to arrays was Fortran's for-loop,
which enumerated an array's indexes,
1, 2,..., while processing the array's elements:
for i = 1 to n by i = i + 1 :
r[i] = r[i] * 2
This example doubles all the values in integer array r.
(Fortran array indexes start counting at 1: 1,2,3,....)
The loop's header line initializes, increments, and tests for
termination an index variable.
The Pascal and C languages also use this form of loop.
Data structures are collections, and a standard way
to process a collection is to examine its elements one at a
time. If the order in which one examines the elements
does not matter, then one might use an iterator
control structure to process the data structure. Iterators
work well with sequences like arrays, lists, stacks,
and queues. A foreach loop is an example of
an iterator that lets you simply examine all the elements of
a sequence.
Here is an example in Python of using a foreach iterator to find
the largest integer in a structure. (Say that r is
an array or stack or list holding nonnegative ints.)
max = -1
for element in r : # in Python, 'foreach' is spelled just 'for'
if element > max :
max = element
print max
The foreach iterator in C# works the same.
Some languages (Ocaml, Python, Miranda)
embed the iterator directly into a representation
of the data structure, so that you can simultaneouly
examine the elements of one data structure
and build a second structure with the results.
For example, say that vec is a list/array of ints
and we wish to construct a new list, vec, that holds
the integers squares. We could write this:
vec = [2, 4, 6]
vec2 = [x*x for x in vec] # sets vec2 to [4,16,36]
This is the same as
vec2 = []
for x in vec :
vec2.append(x*x)
which is the same as
for i = 0 to len(vec)-1 by i = i + 1 :
x = vec[i]
vec2.append(x*x)
It is also possible to add a side condition, e.g.,
we wish to retain only the squares of the odd-valued ints:
vec2 = [ x*x for x in vec if x % 2 == 1 ]
that is,
vec2 = []
for x in vec :
if x % 2 == 1 :
vec2.append(x*x)
These examples are sometimes called (list) comprehensions
4.3.1 Map, filter, and reduce
The iterator control structure (foreach)
lets us examine the elements of a data structure without
listing explicitly all its indexes/keys.
The previous examples showed us combined data/control structures,
where iteration is combined with computation.
The origin of combined control/data structures like comprehensions
follow from some basic principles:
-
map: one wants a control structure that can apply an operation
to each element of a data structure, updating each element in-place in the
structure or building a new data structure with the updated elements in it.
-
filter: one wants a control structure that can examine
the elements of a data structure, selecting and collecting the ones
that satisfy a test condition
-
reduce: one wants a control structure that can combine together
all the elements of a data structure, applying an operation that
leads to one, final answer
Most of the work we do with data structures can be understood with
the concepts of map, filter, and reduce.
One more time, we consider lists (arrays):
For array r and an operation, f, that computes elements
of r,
a map structure might look like this:
map(f, r)
We might use it like this:
answer = map(f,r)
and its behavior would be understood like this:
answer = []
for i = 1 to n by i = i + 1 :
answer[i] = f(r[i])
You can see how this leads to the comprehension-style representation:
answer = [f(e) for e in r] and you can see how there is a set-like
intuition to this: answer = { f(e) | e in r }.
If map was defined to be an in-place update, we would say
map(f,r), and its semantics would be
for i = 1 to n by i = i + 1 :
f[i] = f(r[i])
Next, the filter operation selects elements that satisfy a
boolean condition coded by a function, f, that maps an element
to a boolean. filter(f,r) computes like this:
answer = []
for i = 1 to n by i = i + 1 :
if f(r[i]) :
answer = answer + [r[i]]
return answer
This can be written in the set-like comprehension style, like this:
[ e for e in r if f(e) ].
In this style, you can also see why
map(g, filter(f, r)) is written as
[ g(e) for e in r if f(e) ].
Finally, a reduce operation is useful, for say, adding up all the
integers in an int array or for selecting the largest element in
an array.
The format of a reduce operation is
reduce(f, r, start), such that the operation goes like this:
answer = start
for i = 1 to n by i = i + 1 :
answer = f(answer, r[i])
return answer
For example, if we have
def larger(x,y):
if y > x : return y
else : return x
Then we select the largest element of array r of nonnegative ints like this:
max = reduce(larger, r, -1)
If the starting value (here, -1) is not clearcut, there is a
simplified version of reduce that omits it but then
demands that the data structure, r, possess at least one element,
which is used as the starting value for the reduction.
4.4 Summary
A core language is almost always extended by data structures and
control structures. There are two principles for extension:
-
Data-structure extension principle:
Every kind of data structure may be used as elements for another
kind of data structure; that is, data structures may be nested.
-
Control-structure extension principle:
Every syntactic domain may be extended by control structures.
Since a data structure holds a collection of elements, we also employ
iterator-like operators that systematically let us examine and process
the elements of a data structure. The iterators are based
on the map, filter, reduce principles of data-structure
computation.