
If you knew the name of the file (e.g., www.mtv.com), you could ask for a copy of it to display on your computer. But there was no way to ask, ``find me MTV's website.''
The Alta-Vista search engine was a program that you could ask to find a web page. AltaVista found and downloaded as many html files as it could find. It extracted the words from each file and saved them in a monstrous table that a user could search at www.altavista.com. When you asked to find the page for, say MTV, Alta Vista searched its table for the web pages that mentioned MTV.
See the figures in MacCormick's book. Here's the one from Page 16, which shows three Web pages and the table constructed from them:
(Recall that the entries 1-2, 3-2 for cat signifies that the word occurs in Page 1, position 2, and in Page 3, position 2.) Chapter 2 addresses the issue, ``how do we use the word table to find web pages?'' Read the chapter, and concentrate on Pages 12-19. An example: find all web pages that have the precise phrase, "cat sat":
Indeed, 1-2 matches with 1-3, but 3-2 has no match.
Every computer program is built to satisfy a requirement or a specification. The more precisely stated the requirement, the easier it is to understand how to build a program that meets it.
State, as precisely as you can: what is the requirement that Alta Vista attempts to satisfy? (See the very end of this page for a possible answer.)
It is critical that we generalize from use-cases to a general pattern --- an algorithm --- for looking up Web pages that match an arbitrary phrase (and not just "cat sat"). Here is an algorithm that works for a two-word search phrase:
INPUT: a two-word phrase of form, "Word1 Word2"
OUTPUT: an AnswerList, a list of the numbers of the Web pages that contain the phrase
ALGORITHM:
(0. The AnswerList starts with nothing saved in it.)
1. Extract from the table the list of Page#-Position# pairs for Word1. Call it List1.
2. Extract from the table the list of Page#-Position# pairs for Word2. Call it List2.
3. For each page#-pos# pair in List1,
search List2 to see if there is a pair, page#-(pos#+1).
(that is, the page# is the same and pos# differs by +1)
if yes, then include page# in the AnswerList.
if no, then ignore this pair.
4. Announce all the page numbers in AnswerList
The algorithm must be "precise enough" that we can explain it to a computer in a "computer language" (C, Java, Python, etc.)
INPUT: a list of Web pages
OUTPUT: a table that contains all the words in all the Web pages...
ALGORITHM:
(0. Table starts empty)
1. for each Web page, call it Page#P, in the list of pages,
for each word, W, within Page#P,
...
2. Return the Table.
Here is a "spelling tree" format for the table:
Explain how to use the spelling tree to conduct the search for cat stood: write down the one-by-one steps a computer uses to "read" the relevant "branches"/"links" in the "tree".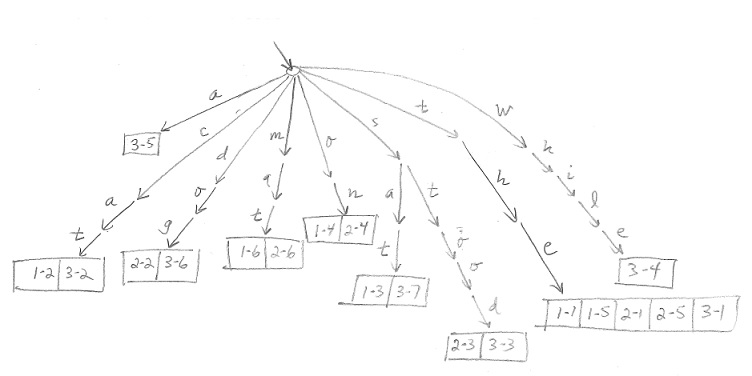
Next, add the contents of this web page to the above spelling tree:
PAGE 4: can my cat stand up
In your data structures course, you will learn how to use pointers/handles to build spelling trees that grow inside computer storage.
But what do we mean by ``relevant''? Alta Vista interprets ``relevant'' as ``mentions the phrase.'' But there should be better definitions, yes? How we define the term, ``relevant,'' leads us to how to build the program....